Amazon Web Services (AWS) Simple Storage Service (S3) enables users to organize and manage data in logical containers known as “buckets”. AWS continues to improve and simplify the bucket creation and configuration process, from simply clicking “Create bucket” in the user interface to enabling creation and configuration through code, via CloudFormation. This article will walk you through how to create S3 buckets via CloudFormation, allowing you to reap the benefits of Infrastructure as Code (IaC) practices.
Get a Free Data Risk Assessment
What is AWS S3?
AWS S3 is a highly-customizable, secure object storage solution. The wide variety of customizations in relation to cost, security, scalability, and durability allow users to fine-tune their architecture to meet business and compliance requirements.
What is AWS CloudFormation?
CloudFormation — Amazon’s IaC service — provides an easy way to create a collection of AWS and third-party resources in a manner much simpler than the traditional specific resource APIs. In its simplest terms, CloudFormation allows you to create and manage your infrastructure or AWS resources across accounts and regions — all via code.
Overview: AWS S3 bucket creation
Creating a bucket may seem like a simple enough task; the intuitive user interface makes things like configuring access control and bucket access logs, enabling encryption, and adding tags an easy process. However, these manual tasks require many specific, individual steps that can complicate the process.
The most common problem we’ve seen is accurate replication. Although a developer may manage to create and configure a single bucket successfully, the probability that they can replicate this process perfectly across multiple accounts and environments is quite low. CloudFormation is the solution to this problem.
S3 buckets with AWS CloudFormation
CloudFormation is used to create and configure AWS resources by defining those resources in a given IaC. Within the definition, a number of keys are used to define specific bucket attributes. This includes — but is not limited to — enabling encryption and bucket access logging. The AWS::S3::Bucket resource is used to build an Amazon S3 bucket.
S3 bucket creation prerequisites

Before proceeding with bucket creation, there are a number of things to consider:
- CloudFormation permissions: Does the user have permissions to create, update, and delete CloudFormation stacks? How about permissions to provision the resources listed in the CloudFormation template?
- Unique names: S3 bucket names must be globally unique, making it impossible to create buckets with the same name across different accounts. This also makes it unlikely that short, simple names will be available. To avoid running into this problem, plan your names well and try to namespace them using the environment or account ID. Alternatively, you can allow CloudFormation to generate random unique identifiers instead of specifying names.
- Future-proofing: If you think future analysis and reporting on a bucket is a possibility, think about how to best organize the bucket structure. For example, it's common practice to create subfolders per time period (year, month, day, etc.). Depending on how long data needs to be accessible, build life cycle rules to delete old objects or move objects between storage classes at fixed intervals.
- Regulatory requirements: Business and regulatory requirements may drive configuration decisions, but regardless of requirements, it's generally a good idea to enable bucket encryption and bucket-logging anyway.
- Version control system: To take advantage of IaC, resource files should be synced to a version control solution, such as git. This allows developers to quickly identify, provision, or roll back iterations of the solution.
How to create an S3 bucket
Create an S3 bucket with encryption and server access logging enabled.
1. Navigate to S3
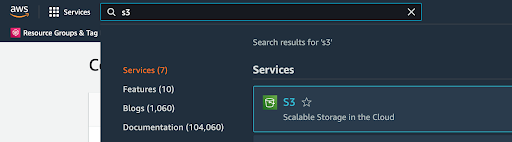
From the AWS console homepage, search for S3 in the services search bar, and click on the S3 service in the search results.
2. Create a new bucket
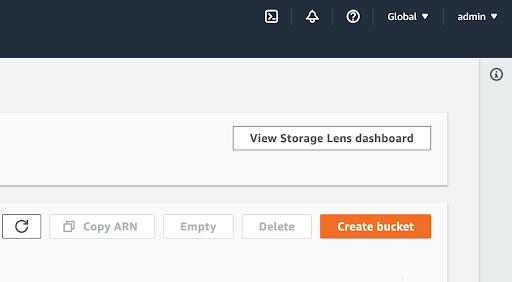
Click on the “Create bucket” button.
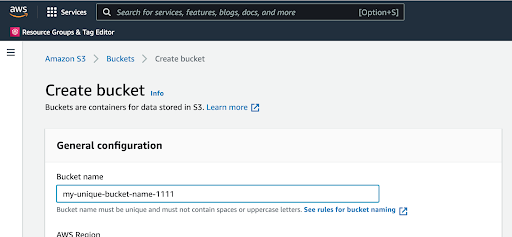
S3 bucket names need to be unique, and they can’t contain spaces or uppercase letters.
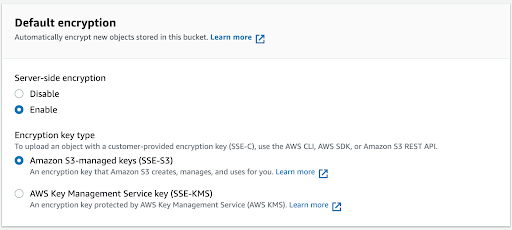
Selecting “Enable” in the server-side encryption options will provide further configuration options. Select “Amazon S3-managed keys (SSE-S3) to use an encryption key that Amazon will create, manage, and use on your behalf.

Click the “Create bucket” button at the bottom of the form, noting that additional bucket settings can be configured after the bucket is created.
3. Additional configuration
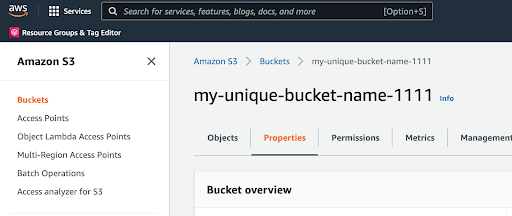
Once the bucket has been created, click into its properties to add additional functionality.

Server access logging can be used to gain insight on bucket traffic. Anytime an asset is accessed, created, or deleted, a log entry will be created. These logs include details such as timestamps and origin IPs. To enable server access logging, click the “Edit” button in the server access logging section of the bucket properties tab.
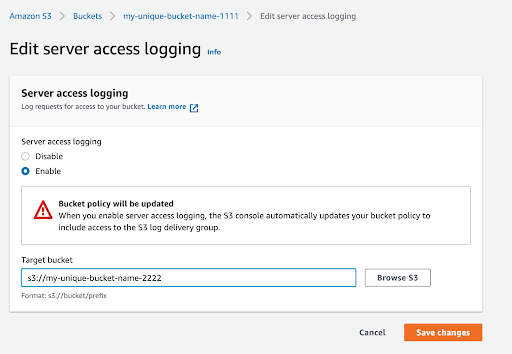
In the edit form, select “Enable”, choose another S3 bucket to send access logs to, and click the “Save changes” button. If there’s not already another bucket to send logs to, create a new bucket and come back to this step once that has been completed.
4. Automate using CloudFormation
We are now going to use infrastructure as code to programmatically repeat this process. Start by deleting any buckets manually created in previous steps so that the same process can be repeated and automated using CloudFormation.
5. Create an infrastructure file
Using the text editor of your choice, create a file named simple_template.yaml and add the following configuration:
AWSTemplateFormatVersion: "2010-09-09"
Description: Simple cloud formation for bucket creation and configuration
Parameters:
BucketName: { Type: String, Default: "my-unique-bucket-name-1111" }
Resources:
AccessLogBucket:
Type: "AWS::S3::Bucket"
Properties:
AccessControl: LogDeliveryWrite
MainBucket:
Type: "AWS::S3::Bucket"
Properties:
BucketName: !Ref BucketName
BucketEncryption:
ServerSideEncryptionConfiguration:
- ServerSideEncryptionByDefault:
SSEAlgorithm: AES256
LoggingConfiguration:
DestinationBucketName: !Ref AccessLogBucket
Outputs:
MainBucketName:
Description: Name of the main bucket
Value: !Ref MainBucket
LogBucketName:
Description: Name of the access log bucket
Value: !Ref AccessLogBucket
This code contains a number of interesting snippets. First, it specifies an AccessLogBucket resource but does not specify a name, which allows AWS to automatically generate a unique name. Under properties, it specifies that the bucket can be used as an endpoint for logs.
Next, it specifies the main bucket, references the user provider bucket name, specifies encryption, and sets the bucket location for logs by simply referencing the AccessLogBucket resource. These two blocks of code have effectively described the infrastructure created manually in previous steps.
Finally, the code returns the two bucket names as outputs so that they can be easily imported into other stacks if required. The final step is to upload the code and actually create the resources.
6. Navigate to CloudFormation
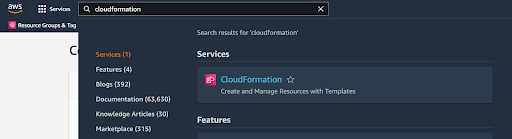
From the AWS console homepage, search for “CloudFormation” in the services search bar, and open the CloudFormation service from the search results.
7. Create a new stack
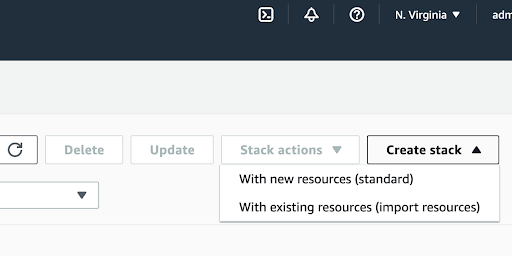
Click “Create stack” and select “With new resources (standard)”.
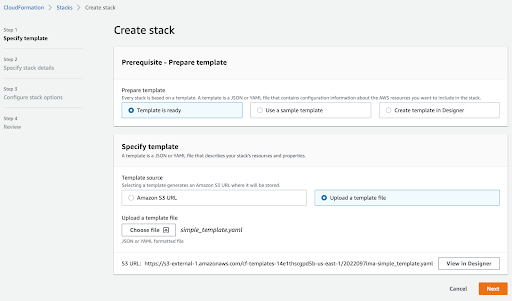
Select “Upload a template file” and click “Choose file” to upload the code. Click “View in Designer” to see a graphical representation of the infrastructure.
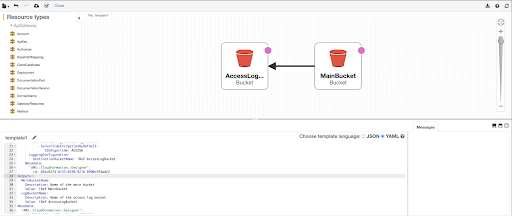
The designer view will display an interactive graph, used to review or continue to build a solution. Once complete, click the upload icon in the top left corner.
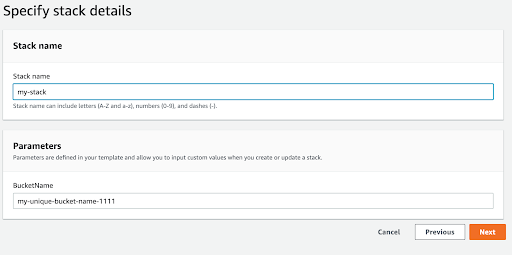
When specifying stack details, use a unique name for both the stack and bucket name. Click “Next” once these have been provided.
On the next screen, scroll to the bottom and select “Next” to stick with default stack configurations.
On the final screen, you will see a summary of what has been completed so far. Scroll to the bottom and click “Create stack” to create our resources.
Once the stack creation process kicks off, a screen appears with progress updates.
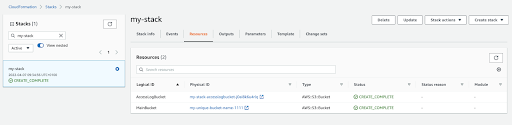
When the stack creation is complete, view all the created resources in the “Resources” tab.
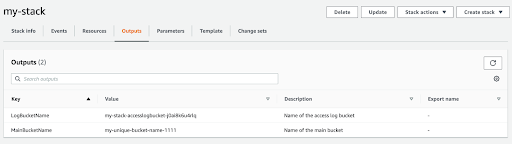
Similarly, the “Outputs” tab will display the outputs configured in code. In this case, those are the MainBucketName and the dynamically generated LogBucketName.
8. Confirm configuration
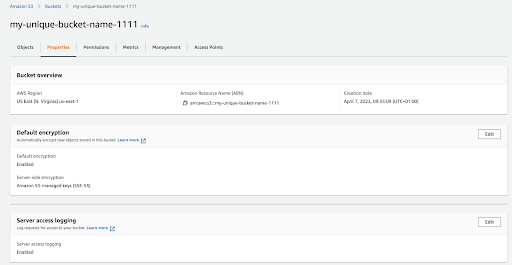
Now that the buckets have been created, they can be inspected in S3. Navigate to the bucket and inspect its properties to confirm default encryption and server access logging have both been enabled.
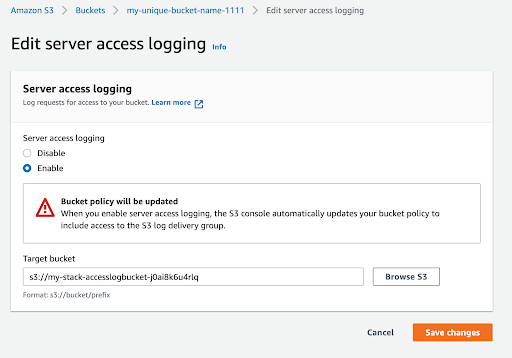
Click the “Edit” button to inspect the server access logging configuration and verify the AccessLogBucket has been configured as the source of log delivery.
And there we have it. Less than 30 lines of code that will create and configure an S3 bucket. This code can be reused over and over to remove human error and create consistent configuration across environments, regions, and accounts.
Additional CloudFormation templates
The above example showed some of the common S3 configuration options. However, there are many more properties available to configure. Check out the official documentation below.
Type: AWS::S3::Bucket
Properties:
AccelerateConfiguration:
AccelerateConfiguration
AccessControl: String
AnalyticsConfigurations:
- AnalyticsConfiguration
BucketEncryption:
BucketEncryption
BucketName: String
CorsConfiguration:
CorsConfiguration
IntelligentTieringConfigurations:
- IntelligentTieringConfiguration
InventoryConfigurations:
- InventoryConfiguration
LifecycleConfiguration:
LifecycleConfiguration
LoggingConfiguration:
LoggingConfiguration
MetricsConfigurations:
- MetricsConfiguration
NotificationConfiguration:
NotificationConfiguration
ObjectLockConfiguration:
ObjectLockConfiguration
ObjectLockEnabled: Boolean
OwnershipControls:
OwnershipControls
PublicAccessBlockConfiguration:
PublicAccessBlockConfiguration
ReplicationConfiguration:
ReplicationConfiguration
Tags:
- Tag
VersioningConfiguration:
VersioningConfiguration
WebsiteConfiguration:
WebsiteConfigurationS3 bucket FAQs
Q: What does S3 stand for?
A: Simple Storage Service.
Q: Will CloudFormation delete the S3 bucket?
A: This can be controlled by the user. By defining a deletion policy for a bucket it can be configured to retain or delete the bucket when the resource is removed from the template, or when the entire CloudFormation stack is deleted. See the official documentation for using the DeletionPolicy attribute.
Q: Is creating an S3 bucket free?
A: Creating a bucket is completely free for anyone with an AWS account. The default limit for the number of buckets in any given account is 100 but there is no limit on bucket size or the number of objects that can be stored in any one bucket. AWS S3 costs are for storing objects. These costs can vary depending on the objects' size, how long the objects have been stored, and the storage class. For full details on S3 costs see the official pricing guide.
Q: Who can create an S3 bucket?
A: The permission required to create a bucket is the s3:CreateBucket permission; if a user or service has been assigned a role with that permission they can create a bucket.
Q: What are the benefits of using Infrastructure as Code (IaC)?
A: Efficient development cycles and fast consistent deployments. IaC aims to eliminate manual administration and configuration processes. This enables developers to focus on writing application code and iterate features faster, at more frequent intervals.
Users of AWS will often require a large number of services, configured in a very specific way and duplicated across development, staging, and production environments. Defining this service architecture using IaC satisfies this requirement. This gives your configuration a single source of truth regardless of the environment. In particular, S3 configuration is extremely important because storage services are prime targets for attackers, due to the potential of accessing sensitive or valuable data.
By following some best practices for structuring AWS S3, and by defining S3 configuration as code, the configuration will remain consistent and secure across environments. Similar to application code, this can go through comprehensive peer review before deployment to production.
For help identifying and protecting sensitive data points in your S3 solution check out The Varonis Data Security Platform.
What you should do now
Below are three ways we can help you begin your journey to reducing data risk at your company:
- Schedule a demo session with us, where we can show you around, answer your questions, and help you see if Varonis is right for you.
- Download our free report and learn the risks associated with SaaS data exposure.
- Share this blog post with someone you know who'd enjoy reading it. Share it with them via email, LinkedIn, Reddit, or Facebook.